In my previous post, I advocated the used of depth for recall as a classifier effectiveness metric in e-discovery, as it directly measures the review cost of proceeding to production with the current classifier. If we know where all the responsive documents are in the ranking, then calculating depth for Z recall is straightforward: it is simply the position of the Z'th responsive document in the responsive ranking. In practice, however, we don't know the responsive documents in advance (if we did, they'd be no need for the predictive review). Instead, depth for recall must be estimated.
The simplest way to estimate is by sampling. We draw a simple random sample from the documents in the predictive ranking, and assess the sampled documents for responsiveness. Take the responsive sample documents, and observe their predicted relevance scores. The Z'th quantile is our estimated cutoff score. Returning all documents with a higher relevance score than this cutoff gives us a production with estimated recall Z.[1]
The one sample (for instance, a control sample drawn before training started) can be reused at each training iteration, albeit at the cost of introducing a sequential sampling bias. Or a new sample could be drawn each time, and the sample documents added to training if a decision to stop were not reached.
Of course, once we're using an estimate, we have to face the risk that our estimates will be in error. To illustrate, we draw five samples of 1,500 documents each, and use each to estimate the cutoff depth to achieve 80% recall at each training iteration for the same GCRIM topic run used in the last post. We then calculate the actual recall achieved if the ranking is cut off at the estimated depth. The results are shown in the following figure, one red line for each sample:
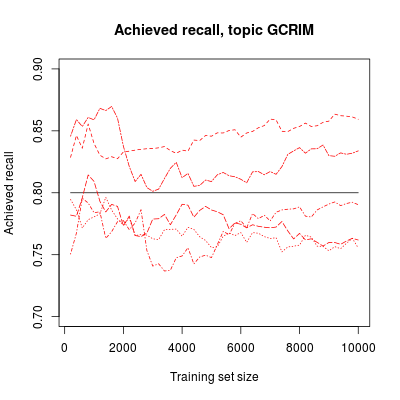
Achieved recall (red) of five 1,500-document samples used to estimate depth for 80% recall after each training iteration of a run against the GCRIM topic.
Achieved recall varies from target, between samples, and for the one sample over time. This variability for the one sample is what will give us sequential testing bias, if we used the control sample to test repeatedly: we're more likely to hit our budget on a cutoff that falls below than above target recall. Nevertheless, the one sample tends to err in the same direction, and roughly the same amount, over time: if you get a sample that overstates achieved recall at the start of training, then it will tend to do so throughout the run. (That would not be the case if a new sample were drawn at each iteration.)
There are different ways of dealing with estimation error. One approach would be to derive a confidence bound: that is, to estimate a cutoff that we are (say) 95% confident will give us target recall or above. Sequential sampling bias would also need to be quantified and dealt with. If the control sample were only used for internal checking, on the other hand, while a separate validation sample were used to select the final cutoff point (which I regard to be best practice), risk is shifted to the producing party, and this risk may be directly integrated into the review manager's cost equation---something that is examined in a forthcoming CIKM paper by Mossaab Bagdouri, Dave Lewis, Doug Oard, and myself, which I intend to discuss in a later post.
[1] See Hyndman and Fan, "Sample Quantiles in Statistical Packages", The American Statistician, 50(4), 1996, for a survey of different quantile methods. Note that for most of the quantile methods, the calculated quantile value will generally not be the relevance score of a specific sampled responsive document, but will be interpolated between responsive scores.