I had the opportunity on Monday of giving a talk on processes for predictive coding in e-discovery to the Victorian Society for Computers and the Law. The key novel suggestion of my talk was that the effectiveness of the iteratively-trained classifier should be measured not (only) by abstract metrics of effectiveness such as F score, but (also) directly by the cost / benefit tradeoff facing the production manager. In particular, I advocated a new ranking metric, depth for recall.
The benefit part of the tradeoff is most simply modelled when the production manager has to achieve a given recall level---say, 75% recall. The recall target could be laid out in the ESI protocol agreed between the parties, or by the internal quality controls of the producing side. A given recall target can always be achieved (if not always known to be achieved) by a ranking and threshold approach. The classifier estimates a relevancy score for each document (a capability offered by statistical classifiers); the collection is ranked by decreasing relevancy score; and we proceed as far down the ranking as is required to achieve the desired recall. Even in a random ranking, X% recall can be achieved by going X% of the way down the ranking.
The cost of the retrieval is the ranking depth, or equivalently the retrieval size. Where the documents retrieved by the predictive coder are manually reviewed prior to production---still a common practice---retrieval size directly represents cost, as the number of documents that must be reviewed. Where manual review is not performed, retrieval size is a proxy for vaguer notions of cost, such as the risk of sanction for over-production, or the danger of inadvertently releasing sensitive material.
The question of interest to the production manager for a given classifier and recall target is: how far down the predictive ranking induced by the classifier do we have to go to achieve the required recall? This is the metric that I refer to as depth for recall.
Of course, the required depth cannot be exactly known without first identifying all the responsive documents in the collection. It can, however, be estimated using a control sample; that is, a test set of documents randomly sampled from the collection, labelled for responsiveness, and kept separate from the training data. To estimate the depth for recall of a given classifier, use it generate a predictive ranking over the control sample. For a recall target of X, find the X percentile responsive control document, and then the next responsive document after that. The relevancy score of the latter document estimates the score at which to threshold the collection to achieve X recall. Lower confidence bounds can similarly be estimated from the control sample, albeit with a bit more statistical work.
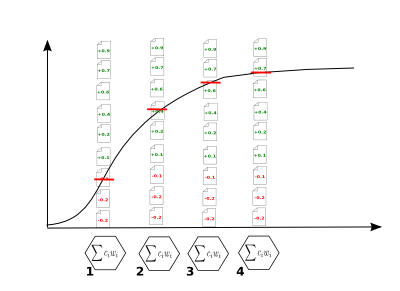
Learning curve as depth for recall on incrementally trained classifier models
With (estimate or bound) depth for recall as our effectiveness metric, the graph of classifier performance over training increments becomes a direct measure of cost to the production manager (see the above figure). The manager can proceed to production at any stage with a statistical guarantee on recall, and knows at each stage what the review cost of so proceeding will be.
Cost to proceed to production, however, is only one of the quantities of interest to the production manager. The other is the cost / benefit tradeoff for performing more training. The benefit is a more effective classifier, and so a smaller depth for recall. The cost is that of paying the subject matter expert (SME) to label the additional training documents---typically a much higher cost per document than manual review, due to the greater expertise required. Here, the cost / benefit tradeoff is not transparent to the production manager: though we know the cost of more training, we can only forecast the decrease in depth for recall that it will accomplish. (This latter tradeoff is the subject of ongoing research work at the E-Discovery Lab of the University of Maryland by Mossaab Bagdouri, Dave Lewis, Doug Oard, and myself.)
With this combined cost / benefit model, we can make some useful observations about the predictive coding process. First, predictive coding is not so much a classification as a prioritization task. It aims to save client cost by improving the quality of the ranking over the collection, and decreasing the processing depth required of the review step. And second, holding depth for recall fixed as a proportion of collection size, we can see that the optimal amount of effort to place in training grows with the size of the collection. With small collections, a relatively high proportional depth for recall leads to a manageable absolute retrieval size, and a simple ranked search followed by a couple of iterations of training may be sufficient; for a larger collection, however, proportional depth for recall needs to be much tighter for post-retrieval review costs to be supportable.
The model therefore allows us to answer the frequent question of, how large does the collection have to be for predictive coding to be worthwhile? The answer is that, setup costs aside, any non-trivial size of collection can benefit from predictive coding; with smaller collections, we simply require less training effort to bring review costs within budget.